
The Background
The PGA TOUR records data from every shot taken by every player in every round of every tournament. Primarily, this data is used to calculate Strokes Gained statistics. The stat seeks to express how a player’s total score is impacted by each individual shot (stroke). In other words, if a player hits his (unfortunately this data is only captured for the men’s tour) drive 25 yards longer than the average player, how dramatically was his likely score improved? Likewise, if an approach shot finds a greenside bunker, what was the negative impact on his likely score. I won’t digress further into the nuts and bolts of the stats, but the statistic has played a major role in bringing about a data-driven revolution in the game and was the impetus for the initial collection of the data, which I will in turn be collecting, so I figured it was worth mentioning.
Strokes gained has been a massive success and I commend the PGA (and the volunteers who actually record each shot) for the undertaking, but I have been continually disappointed that none of the data has ever been made public. It would be fantastic to allow enthusiasts and businesses alike to mine the data for further insights, create novel visualizations, and develop entirely new fan experiences, yet that data remains inaccesisble in raw form to the public. Admittedly, these goals may be a touch unrealistic, but I would be more understanding if the PGA was at least monetizing the data, but as far as I can tell they are not. So, why just let it sit there?
Ok, so the PGA has actually created a really cool web app for visualizing shots for ongoing tournaments, but there’s so much more potential than that. I should also give praise to that tool, because, well, it’s exactly how I’m going to collect the data.
So, what’s my goal here? As much as I would love to make the data public to help bring about those lofty goals I mentioned, I just can’t do it. I’m comfortable in my rights to access public data on the internet that isn’t protected by any a sort of authorization, but I’m less comfortable publicizing that data for anyone to download. Even if it is legal (I wouldn’t be selling it which kinda maybe would make that ok), I’ll still respect the PGA’s decision to keep control over data they (via volunteers) collected. I won’t make any of this data public directly. I really just want to make some cool stuff with it. If you’re reading this and want to do the same, you’ll have use this post as a guide and collect the data yourself.
The Source
The PGA TOUR’s web application for viewing real-time shot data, TOURCast, is really great and I would highly recommend that anyone with an interest in golf or 3D visualization check it out. The below image gives an example of the user experience.
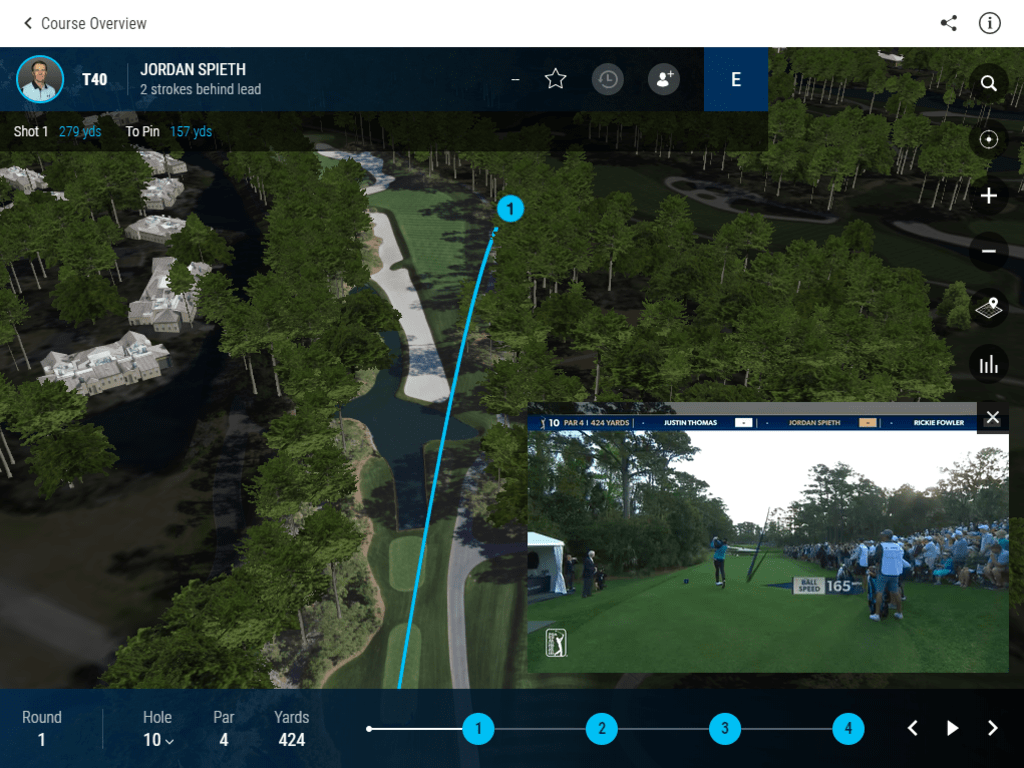
The user can select a player to follow, in this case Jordan Spieth, at which point the app will update the 3D model with the player’s shots as they happen. Users have the ability navigate around the map and zoom into the shot location with quite a bit of accuracy.
With my goal being to extract the shot location data, I was initially worried that the shot visualizations may be baked-in graphically in a way that would make extracting the raw location data difficult or even practically impossible. Luckily, after opening up the network tab of Developer Tools, I noticed that before any new shots were rendered, a request was made for a holeview.json file.
The contents of the JSON blob were promising, with fields titled from_x, from_y, from_z, x, y, and z, it was clear some sort of location information could be accessed from this API. Looking at the numbers in these fields, they seemed to contain what the field names indicated, a beginning 3D point and an end 3D point, but the values didn’t seem like any coordinate system I recognized. I hoped the values would contain GPS coordinates, which range from -90:+90 and -180:+180, but the values ranged in the tens of thousands. This would also most likely rule out a local projected UTM (or similar) coordinate system as those values are typically much larger, because your location is likely a long way from the origin of the coordinate system. What seemed most likely is that the coordinates were in some sort of arbitrary local cartesian system, where some corner of the 3D model is the origin. This means I’ll have to come up with some scheme down the road to convert these coordinates to some known system, but that’s a problem for another day.
As an aside, this coordinate system approach seems like a bad choice, because the shots are presumably captured in GPS coordinates on the course, so the backend must have to store a conversion for each course’s model and apply that conversion for each newly uploaded point (and store it, unless the conversion is done on the fly for each request). The models appear to be constructed by taking satellite imagery as the base, probably applying elevation data to create a 3D terrain model, and finally, pasting on some fake 3Dish trees and bushes. With satellite data as the base, the model should be already geo-referenced which would allow almost any 3D geospatial framework to easily place GPS points directly, no conversion required. Of course, I don’t know the full details of the implementation so I’ll stop short of judgment and just say that I found the whole thing odd… maybe just because it made my life more difficult.
Now that I know the coordinates are arbitrary, I really need them to at least be in some sort of sane units (e.g. yards or meters). If the units are relative to the model size, or something like that, I’ll have to jump through even more hoops figure that out. The holeview.json file contains a distance string field in the form “${number} yards” for each shot. So at the very least, I know each shots distance, but ideally I want to easily determine metrics like how far apart are two end points, for which, I still need to know the units of the shot coordinates. With a breath-hold I calculate the distance between the start and end points. I quickly see that the value matches that of the distance field. Success. If that hadn’t been the case, I might have shelved the whole project due to the annoyance getting the data into some usable form, so I was quite happy I was able to continue.
The Scrape
Note: I won’t be making any scraping code public. I’ll describe the structure of the data, but I want to spare the PGA TOUR’s servers of people who aren’t interested enough to write the code themselves. I’ll happily share code for the organization and visualization of the data in future posts. Please scrape ethically
Now the time came to collect the data. The web app queries the holeview.json files from routes of the following form /r/xxx/xxxx/xxx/x/x/xx/holeview.json with an example request being r/012/2020/012/1/2/21/holeview.json. The json file contains a tournament_id, course_id, season_year, tour_code, group_number, hole_number, and round round_number fields, which all correspond the the route that was used to download the file. So almost immediately, I was able to determine that the route pattern is as follows: /r/:tournament_id/:season_year/:course_id/:round_number/:hole_number/:group_number/holeview.json. For those not familiar with golf tournaments, players are grouped with one or two other players for the duration of a round (18 holes). Each holeview.json file contained the shot data for all the shots of every player in the group for that hole. Now I know the structure, but I crucially don’t know the tournament and course Ids for all of the events on tour. I didn’t even know if old tournament data was still available via the API.
I poked around the PGA’s website to see if there might be some tournament ledger that would have the backend Ids stored in a request or HTML somewhere, but couldn’t find anything. I decided to write a simple script to start at tournament_id=1 and course_id=1 (and values I knew would exist for the other fields, e.g. hole_number=1) and see if I can work out some of the ids for other tournaments, assuming historical data is even available. I resolved not to just hit the tour’s servers with a million 404’s (3 digit Ids for tournament and course), so I was hoping they would start the Ids at or near zero. Luckily, the first 200 response came at tournament_id=002 and course_id=002. Manually modifying the year, I found out the data only goes back to 2020, not great but at least I have some depth of data beyond the current year’s tournament. Also promising was the fact the tournament and course id matched, which would mean I could scrape all the 2020 tournaments in just 1,000 requests. As it turns out, some tournament and course Ids do not match, but I decided to deal with those as they came up as I can simply go to the tourcast page for an ongoing tournament and find the Ids that way. I ran the script on an AWS instance and uploaded the JSON files to s3 for later parsing and to serve as a long-term backup for my eventual database. With this approach, I was able to grab the data for about 10 tournaments and had a pipeline to collect the data for future tournaments as they completed.
The Next Steps
With the data sitting in thousands of JSON files, I need to create a pipeline to consume the raw data and get it into some sort of defined schema. I’ll detail that undertaking in the next post.